
Verdun 1916 : quand la presse était censurée
Grâce à la fouille de données, rédécouvrez la censure dans la presse de l'époque.

Journal des débats politiques et littéraires, 14 avril 1916
Contenu autorisé, contenu censuré
Le 21 février 1916, l’artillerie allemande déverse un million d’obus sur les lignes françaises. La bataille de Verdun vient de débuter. Mais en une du numéro du 22 février du Journal des débats politiques et littéraires, n’est publié que le communiqué officiel du 20 quant à la situation militaire. En dernière page, le communiqué de l’après-midi présente la version autorisée de la situation sur le front pour la journée du 21 : « Faible action des deux artilleries sur l’ensemble du front sauf au nord de Verdun où elles ont eu une certaine activité ». L’accès à l’information subit une double entrave, temporelle (la presse informe de la situation militaire d’après les communiqués officiels, qui souffrent des délais de transmission des informations au ministère de la Guerre, puis de rédaction et de diffusion) et institutionnelle (la censure militaire préventive a été acceptée [1] par les organes de presse et légiférée à l’été 1914).
Le 23 février, le lecteur de la presse quotidienne n’est toujours pas en mesure d’appréhender l’importance de l’offensive allemande (la veille, l’artillerie allemande a tiré son deuxième million d’obus, les pertes françaises sont très lourdes) : « Dans toute la région de Verdun, les deux artilleries ont continué à se montrer très actives. » (communiqué daté du soir du 21, en première page) ; « Continuation de l’activité d'artillerie dans la région de Verdun. Les Allemands ont attaqué hier en fin de journée nos positions à l'est de Brabant-sur-Meuse, entre le bois d'Haumet et Herbedois. Ils ont pris pied dans quelques éléments de tranchées avancées et poussé par endroits jusqu'aux tranchées de doublement. Nos contre-attaques les ont rejetés de ces dernières. » (communiqué de l’après-midi du 22, en dernière page). Il faut attendre le 24 pour voir apparaître une carte de Verdun dans le Journal des débats politiques et littéraires, et l’Humanité titrer sur la « bataille autour de Verdun ».
Mais les effets du contrôle de l’information se manifestent aussi dans la forme même de la publication, par son « blanchiment ». Les commissions de censure appliquent des consignes d’ordre politique ou militaire (le bureau de la presse du ministère de la Guerre en édictera plus de mille entre 1914 et 1919 [2]), qui conduisent à caviarder mots, passages ou articles complets. Le numéro du 22 février donne un exemple du premier cas (il est ici question de désamorcer le sujet polémique des « planqués de l’état-major ») :

et dans le numéro du 24, un passage relatif à la situation militaire (probablement du front de Verdun) a été censuré :

Ces « blancs », réalisés directement sur la forme d’impression en passant au burin l’œil des caractères déjà composés, ne sont que la face visible et marginale d’un système de censure opérant derrière la scène. Car une organisation efficace du contrôle de l’information (et de la propagande) implique que les premières épreuves soient soumises aux censeurs, puis renvoyées aux rédactions avec les modifications exigées, et enfin représentées pour une dernière validation. Les blancs ne sont que la trace d’une demande de censure réalisée de manière abrupte ou tardive, juste avant le tirage, du fait d’aléas survenus dans le processus lui-même : retard dans l’examen des épreuves, double censure (civile puis militaire), censure de contenus déjà validés (dépêches d’agence de presse, communiqués officiels alliés) [3].
Mais comment repérer ces blancs (quand on est historien, chercheur ou simple amateur) ? Un dépouillement manuel est toujours possible (fût-il numérique). Mais si l’on souhaite obtenir un large panorama des effets de la censure durant la Grande Guerre (les titres de presse d’information, d’opinion, nationale ou régionale ayant appliqué avec plus ou moins d’empressement les directives du bureau de la presse), il sera laborieux… Fouiller les métadonnées peut alors aider.
Décrire les contenus avec des métadonnées
Un numéro de presse numérisé se présente généralement sous la forme d’images, de textes océrisés (OCR, Optical Character Recognition) et d’un manifeste décrivant le document (titre du journal, date de publication, date de numérisation, etc.). Il est également possible d’enrichir cette description par la structure logique du numéro : identification des articles et de leur titre, des types de contenu, etc. Cette méthode de structuration, dite OLR (Optical Layout Recognition), a été appliquée à six quotidiens des collections de la BnF durant le projet européen Europeana Newspapers, corpus couvrant la période 1814-1945 et constitué de 150 000 numéros.
De ce corpus numérique, il est aisé de dériver un jeu de métadonnées descriptives pour chaque numéro : métadonnées bibliographiques (titre du journal, date de publication) et relatives aux contenus, à leur type ou à leur forme, à l’aide de métriques quantitatives (nombre de pages, articles, mots, illustrations, publicités, etc.). Des scripts sont utilisés pour extraire certaines métadonnées du manifeste (au format METS) décrivant le numéro (par exemple le nombre d’articles) ou des fichiers OCR (nombre de mots, d’illustrations, etc.). Le jeu de métadonnées ainsi généré contient environ 4,5 millions de métadonnées élémentaires.
Découvrir le vide en le visualisant
Les techniques de visualisation de données permettent de découvrir sens et information cachés dans de grands volumes de données. Ainsi une visualisation de la densité de mots par page du Journal des débats politiques et littéraires (1814-1944) fait apparaître des valeurs singulières, éloignées de la moyenne d’une période donnée. Ces singularités peuvent aussi bien révéler des numéros riches en illustrations (qui s’avèrent souvent être des suppléments illustrés : 2 mai 1899, plan de l’Exposition universelle de 1899) que des pages moins denses en texte. Et à quoi aboutit l’acte de censure sinon à la disparition du texte ? (Tant pour le lecteur que pour l’OCR…) Ainsi cette page d’un numéro de mai 1915 présentant un blanc sur trois colonnes.
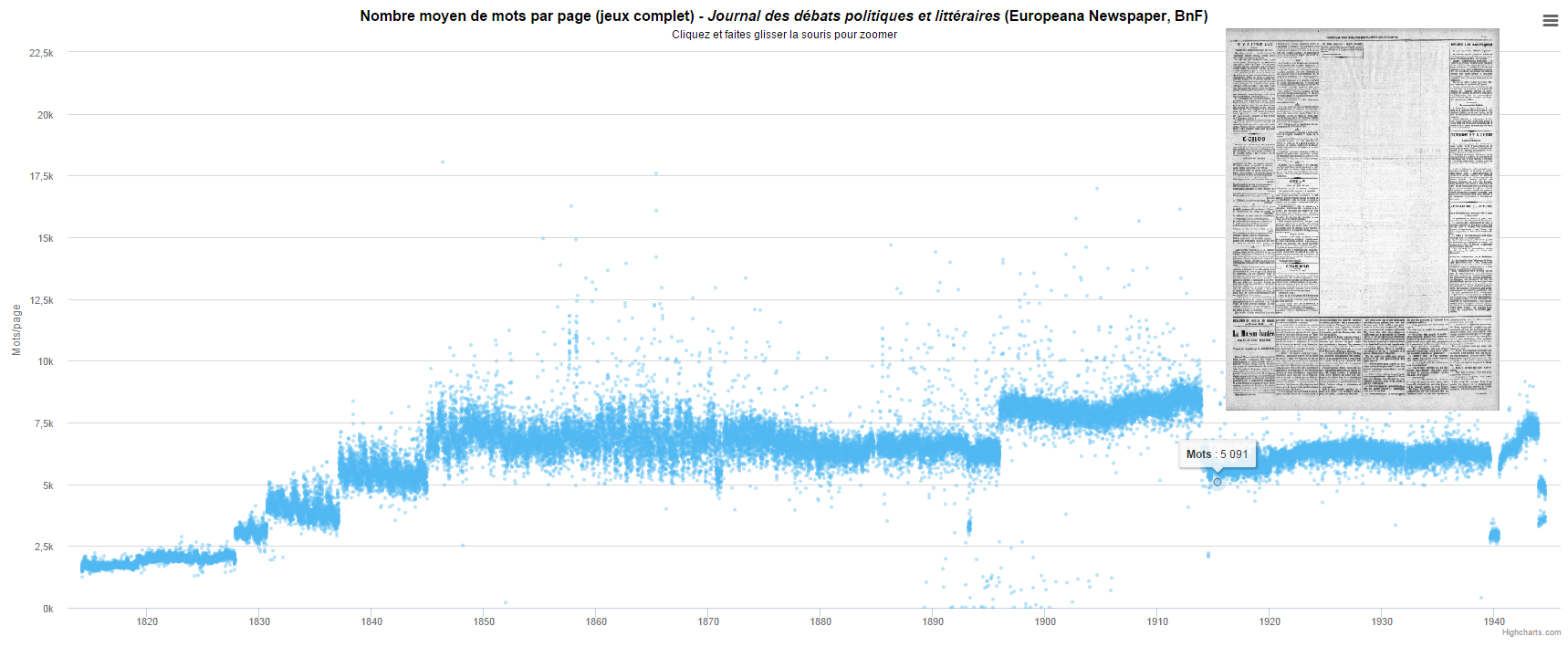
Nombre moyen de mots par page (JDPL)
Faire parler les métadonnées
Cette méthode visuelle atteint ses limites lorsqu’il est nécessaire d’identifier automatiquement les pages censurées. BaseX est une de ces solutions simple et efficace permettant d’agglomérer tous les fichiers XML de métadonnées et d’interroger l’ensemble avec des requêtes XPath/XQuery. Ce mode d’interrogation servira à identifier dans le corpus les types de contenu singuliers découverts par la visualisation, et notamment les pages censurées, lesquelles présentent un nombre de mots inférieur à la moyenne. La requête FLWOR suivante cherche les pages de une du JDPL durant la période 1914-1918 :
<result>
{for $annee in ("1914","1915","1916","1917","1918")
return
let $moy := avg(//metad[matches(//date,$annee) and
(matches(//titre,"Le Journal"))]/../contenus/page[1]/
[blocIllustration=0]/nbMot)
for $pages in //analyseAlto[(matches(//titre,"Le Journal ")) and
(matches(//date,$annee))]/contenus/page[1]
where $pages/blocIllustration=0 and (1.03*$pages/nbMot) < $moy
return ...
Cette requête présente une faiblesse majeure, car s’appuyant sur une moyenne statistique peu fiable (titraille, publicités et illustrations influençant la densité en mots). Cependant, paramétrée avec un seuil de 3 %, elle conduit à l’identification de 45 % des passages censurés et ne produit que 30 % de faux positifs.
Les « blancs » identifiés peuvent alors être visualisés sous la forme d’une frise temporelle, et cette dernière enrichie avec une moyenne des cas de censure par mois, ou encore par les principaux jalons de la bataille. Dans cette optique, la visualisation de données facilite également redécouverte et réappropriation des documents décrits par ces données [4].
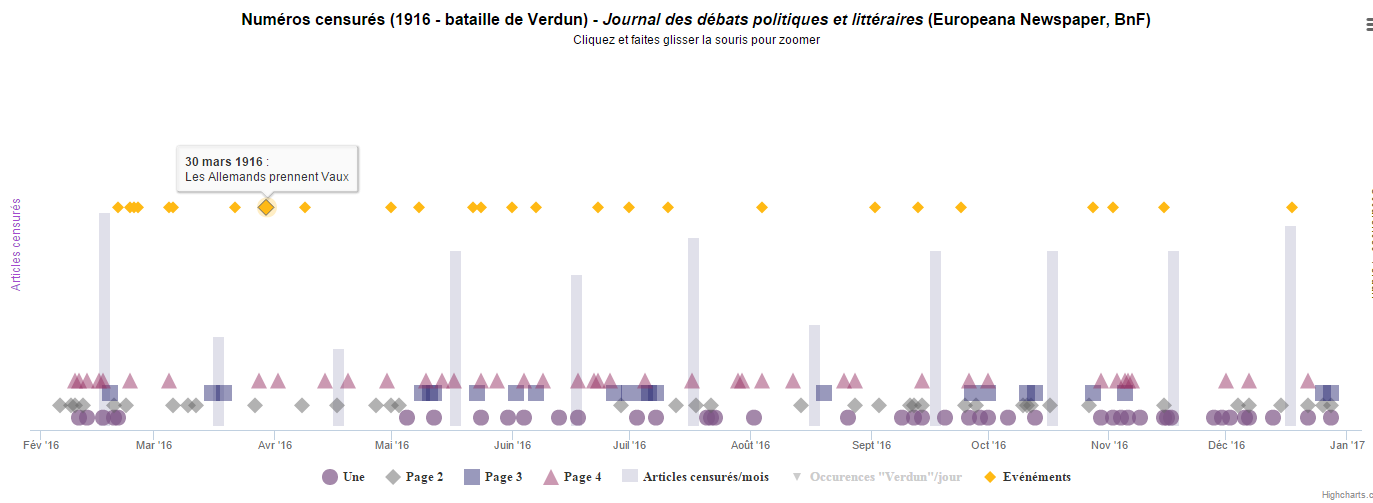
Cas de censure (JDPL, 1916)
Conclusion
Cette expérimentation a montré que des métadonnées descriptives d’une collection de presse, a priori peu disertes, s’expriment haut et fort pour peu qu’on les réunisse en une large assemblée. Ce constat surprenant s’explique par le type documentaire ciblé, la presse quotidienne, sujet idéal pour une structuration de type OLR et partant la création d’un jeu cohérent de métadonnées sur une longue période.
Par ailleurs, le mode opératoire choisi rend cette expérimentation généralisable, ce à double titre : le traitement OLR est désormais un standard en matière de numérisation des collections patrimoniales de presse ; une grande variété d’outils de fouille et de visualisation de données sont disponibles et ne nécessitent le plus souvent que des compétences informatiques élémentaires.
Enfin, il faut espérer que ce jeu de métadonnées dérivées trouvera chez les étudiants et chercheurs en humanités numériques, histoire de la presse, science de l’information, etc. son public d’utilisateurs et participera à fonder des terrains de recherche fertiles.
Sources
Les scripts, les jeux de données dérivées et les graphes décrits dans ce post sont disponibles, ainsi qu’un article présentant d’autres cas d’usage de ces méthodes de fouille et de visualisation de données : http://altomator.github.io/EN-data_mining
[1] Christian Delporte, Antoine Flandrin, « En 1914, la presse accepte la censure parce que la France participe à l'effort de guerre », Le Monde, 18 juillet 2014.
[2] Olivier Forcade, « Voir et dire la guerre à l’heure de la censure (France, 1914-1918) ». In Le Temps des médias, 2005/1 (n° 4).
[3] Aurore Pinonos, Censure et propagande du Progrès, du Nouvelliste et du Salut Public au commencement de la Première Guerre mondiale. Diplôme national de master, ENSSIB, Lyon, 2014.
[4] E. Aiden, J.-B. Michel, Uncharted: Big Data as a Lens on Human Culture. New York: Riverhead Books, 2013
Ajouter un commentaire